Article Text

Abstract
Background Determining heart failure (HF) phenotypes in routine electronic health records (EHR) is challenging. We aimed to develop and validate EHR algorithms for identification of specific HF phenotypes, using Read codes in combination with selected patient characteristics.
Methods We used The Healthcare Improvement Network (THIN). The study population included a random sample of individuals with HF diagnostic codes (HF with reduced ejection fraction (HFrEF), HF with preserved ejection fraction (HFpEF) and non-specific HF) selected from all participants registered in the THIN database between 1 January 2015 and 30 September 2017. Confirmed diagnoses were determined in a randomly selected subgroup of 500 patients via GP questionnaires including a review of all available cardiovascular investigations. Confirmed diagnoses of HFrEF and HFpEF were based on four criteria. Based on these data, we calculated a positive predictive value (PPV) of predefined algorithms which consisted of a combination of Read codes and additional information such as echocardiogram results and HF medication records.
Results The final cohort from which we drew the 500 patient random sample consisted of 10 275 patients. Response rate to the questionnaire was 77.2%. A small proportion (18%) of the overall HF patient population were coded with specific HF phenotype Read codes. For HFrEF, algorithms achieving over 80% PPV included definite, possible or non-specific HF HFrEF codes when combined with at least two of the drugs used to treat HFrEF. Only in non-specific HF coding did the use of three drugs (rather than two) contribute to an improvement of the PPV for HFrEF. HFpEF was only accurately defined with specific codes. In the absence of specific coding for HFpEF, the PPV was consistently below 50%.
Conclusions Prescription for HF medication can reliably be used to find HFrEF patients in the UK, even in the absence of a specific Read code for HFrEF. Algorithms using non-specific coding could not reliably find HFpEF patients.
- Epidemiology
- Electronic Health Records
- Heart Failure
Data availability statement
Data may be obtained from a third party and are not publicly available. No data are available. No data area available for onward sharing from this study.
This is an open access article distributed in accordance with the Creative Commons Attribution Non Commercial (CC BY-NC 4.0) license, which permits others to distribute, remix, adapt, build upon this work non-commercially, and license their derivative works on different terms, provided the original work is properly cited, appropriate credit is given, any changes made indicated, and the use is non-commercial. See: http://creativecommons.org/licenses/by-nc/4.0/.
Statistics from Altmetric.com
WHAT IS ALREADY KNOWN ON THIS TOPIC
Determining heart failure (HF) phenotypes in routine electronic health records (EHR) is challenging, however, despite this, and the fact that the two major HF phenotypes are managed very differently, these data sources are increasingly being used for research and care quality assessments. A literature review did not identify any studies describing algorithms for partitioning HF with preserved ejection fraction (HFpEF) from HF with reduced ejection fraction (HFrEF) using nationwide EHR.
WHAT THIS STUDY ADDS
This prospective validation study showed that prescriptions for HF medication could reliably be used to identify HFrEF patients in the UK. However, algorithms using non-specific HF codes and structured clinical parameters could not reliably identify a HFpEF patient population.
HOW THIS STUDY MIGHT AFFECT RESEARCH, PRACTICE OR POLICY
The results of this study iterate the complexities of using EHR for HF phenotyping. Future validation studies should focus on developing advanced natural language processing tools to capture left ventricular ejection from unstructured data such as text files to accurately support HF phenotyping in EHR.
Background
Although the clinical syndrome of heart failure (HF) is characterised by symptoms of breathlessness and fatigue, there are two specific phenotypes, which can be difficult to discern in the absence of imaging data. However, partitioning patients into the one of the two major phenotypes (HF with reduced ejection fraction—HFrEF) and HF with preserved ejection fraction—HFpEF) is critical since the aetiology, prevalence, prognosis and therapeutic approaches between HFpEF and HFrEF are different.1 2
In the UK, electronic health records (EHRs) potentially provide an excellent resource for understanding the natural history of diseases, their management and how this may change over time, and for comparative effectiveness research to explore quality of care. The use of EHR for these activities in HF is limited since clinical features between the two major phenotypes are the same, while the imaging data required to make the differentiation are rarely incorporated into primary care EHR, despite the need for fidelity in observational and interventional research
Moreover, although diagnosis-specific Read codes for the HF phenotypes do exist (eg, 33BA.00: Impaired left ventricular (LV) function for HFrEF, G583.11: HF with normal ejection fraction for HFpEF),3 4 more than 70% of the HF diagnoses recorded in primary care EHR have non-specific HF codes such as ‘HF’, ‘congestive HF’ (eg, G580.00: congestive HF).4 Hence, before using the data from EHR, a key first step is to establish and validate algorithms that can essentially act as proxies to LV ejection fraction (EF) and thereby differentiate between HFrEF and HFpEF.
The aim of this study was to develop and validate algorithms capable of identifying and differentiating between HFrEF and HFpEF using Read codes in combination with additional patient characteristics and medication data in a randomly sampled primary care population in the UK. Our prespecified secondary aim was to explore whether additional subtypes of HF such as HF with mildly reduced EF could be identified.
Methods
Data sources
We used The Healthcare Improvement Network (THIN), an electronic medical data collection scheme that sources anonymised patient data from more than 3.7 million active patients across 587 general practices in the UK.5 The longitudinal patient records began prospective data collection in September 2002, and now include approximately 55 million patient-years of follow-up, or nearly 10 years per patient. The THIN database accounts for around 6% of the British population and is representative of the population in terms of age, gender, medical conditions and death rates.6 7 THIN-contributing general practices electronically record all conditions and symptoms during patient consultations using the Read coding system and a similar individual clinical filing system including recording of patient diagnoses and comorbidities. In addition to medical diagnoses, information on prescriptions, tests requested, laboratory results and referrals to secondary care is also stored electronically. THIN data are subjected to computerised validation to quantify the completeness and accuracy of recording, and structure of the database coupled with a contract with the contributing General Practices (GPs), allows for sending of questionnaires to GPs. Multiple validation studies have been performed using the THIN database, particularly for confirming its precision in pharmacoepidemiology research.7–9
Study population
The study population consisted of a random sample of 500 individuals with HF codes (HFrEF, HFpEF or non-specific HF) selected from all participants registered in THIN database between 1 January 2015 and 30 September 2017. To be included, individuals needed to be 18 years of age or older, have a diagnosis of HF defined by either specific or non-specific codes suggestive of HF (online supplemental table S1), be registered at their general practice for at least 1 year prior to study start and have at-least 6 months of historical data. Patients with a history of congenital heart disease, rheumatic heart disease, primary valvular disease, infiltrative cardiomyopathies (sarcoidosis, amyloidosis etc), hypertrophic cardiomyopathy and constrictive pericarditis were excluded. People with multiple HF codes (eg, those with both non-specific HF and specific HF codes were excluded.
Supplemental material
The GP of each selected patient was sent a questionnaire consisting of seven questions (online supplemental table S2) requesting confirmation of HF status as well as any specific information from individual’s records such as echocardiograms, laboratory tests including HF biomarkers (natriuretic peptides), hospital cardiology outpatient and discharge letters (figure 1).
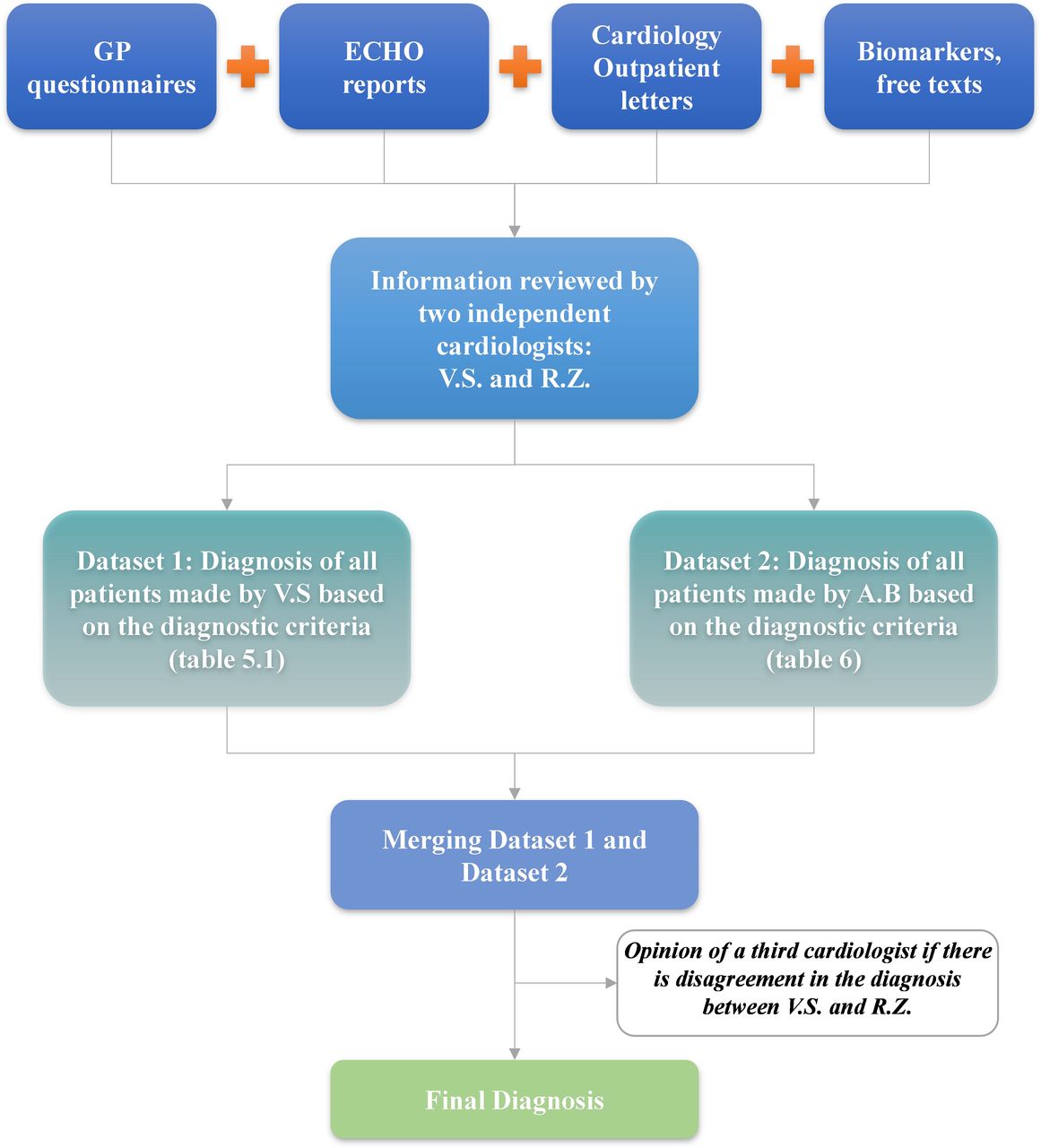
Methodology for inclusion into the study. GP, General Practitioner.
Algorithms for identification of different HF phenotypes
The algorithms consisted of various combinations of Read codes and additional information such as whether an echocardiogram was requested, and if possible the results, HF medications including ACE inhibitors (ACEI)/angiotensin receptor blockers, beta-antagonists (beta-blockers), mineralocorticoid receptor antagonists (MRA) and loop diuretics. In addition, algorithms for HFpEF were built based on the clinical risk factors associated with a diagnosis of HFpEF and from the most recently published H2FpEF score.10 The algorithms were constructed from binary presence or absence of variables (eg, diabetes: yes/no, hypertension: yes/no) (box 1).
Algorithms for HFrEF and HFpEF
Algorithms for HFrEF
Definite HFrEF codes+3/3 guideline directed treatments.
Definite HFrEF codes+2/3 guideline directed treatments.
Definite HFrEF codes.
Possible HFrEF codes+3/3 guideline directed treatments.
Possible HFrEF codes+2/3 guideline directed treatments.
Possible HFrEF codes.
Non-specific HF codes+3/3 guideline directed treatments.
Non-specific HF codes+2/3 guideline directed treatments.
Non-specific HF codes+3/3 guideline directed treatments+ECHO.
Non-specific HF codes+2/3 guideline directed treatments+ECHO.
Algorithms for HFpEF
HFpEF codes.
HFpEF codes+loop diuretics.
Non-specific HF codes+loop diuretics.
Non-specific HF codes+loop diuretics+atrial fibrillation.
Non-specific HF codes+loop diuretics+hypertension+atrial fibrillation.
Non-specific HF codes+loop diuretics+obesity.
Non-specific HF codes+loop diuretics+hypertension
Non-specific HF codes+loop diuretics+elderly.
Non-specific HF codes+loop diuretics+diabetes.
Non-specific HF codes+loop diuretics+chronic kidney disease.
Non-specific HF codes+loop diuretics+coronary artery disease.
ECHO, echocardiogram, HF, heart failure; HFpEF, heart failure with preserved ejection fraction; HFrEF, heart failure with reduced ejection fraction.
HFrEF algorithms were based on various combinations of: (1) One of the three codes: ‘Definite HFrEF’ (for example diagnosis codes of systolic HF), ‘Possible HFrEF’ (eg, cardiomyopathy) or non-specific HF (for example congestive HF) and (2) Use of guideline directed medical therapy (GDMT) as predefined above. HFpEF algorithms were based various combinations of (1) One of the two HF codes specific for HFpEF (eg, diagnosis codes of HF with normal ejection fraction (EF)), or non-specific HF codes (eg, congestive HF), (2) Use of loop diuretics: furosemide, torasemide, bumetanide or ethacrynic acid and (3) Risk factors for HFpEF, taken from previous studies and the H2FPEF score including obesity (body mass index >30 kg/m2), hypertension, atrial fibrillation, older age (>65 years), diabetes mellitus and chronic kidney disease.
Outcomes of interest
The positive predictive values (PPVs) of each of the predefined algorithms used to identify physician-confirmed HFrEF and HFpEF from the EHR were calculated using individual patient information supplied by GPs . The physician-confirmed diagnosis was verified based on the current European Society of Cardiology guidelines from clinical signs, imaging information (echocardiogram), hospital letters and biomarker results recorded on the bespoke questionnaire sent to the GPs of patients included. Two independent cardiologists (VS and RZ), blinded to the EHR data, reviewed all data and categorised patients into HFpEF or HFrEF. We took our initial definition of HFrEF to include all patients with any degree of reduced EF (LVEF <50%) but in order to explore the utility of our algorithms in defining the new subgroups of impaired EF we subdivided this group into those with HFrEF (<40%) and those with HF mildly reduced EF (HFmrEF: ≥40% to 49%).11 12
Statistical analysis
Sample size estimations were based on the predicted response rate to the questionnaire and the proportion of those with a HF code that actually had either HFrEF (~70% to 80% from previous work including the UK National Quality and Outcome framework) or HFpEF. We set our target for a PPV for each algorithm as 0.85 to make it at least as good as clinical assessment based on guidelines. Hence for HFrEF, with 130 patients in the sample, to aim for a PPV of 0.85 the 95% CI is 0.78 to 0.89. For HFpEF on the other hand, with a proportion of 0.3% and the same PPV target, 130 patients gives a 95% CI of 0.72 to 0.92. CIs for PPV were estimated using the method from Mercaldo et al.13
Throughout, results are presented as mean±SD when normally distributed, and as medians and IQR when not. Differences between groups were compared using the χ2 test for categorical data, and, depending on distribution, continuous data were compared with analysis of variance or the Kruskal-Wallis test. All analyses were performed with STATA MP64 V.15 (StataCorp).
Results
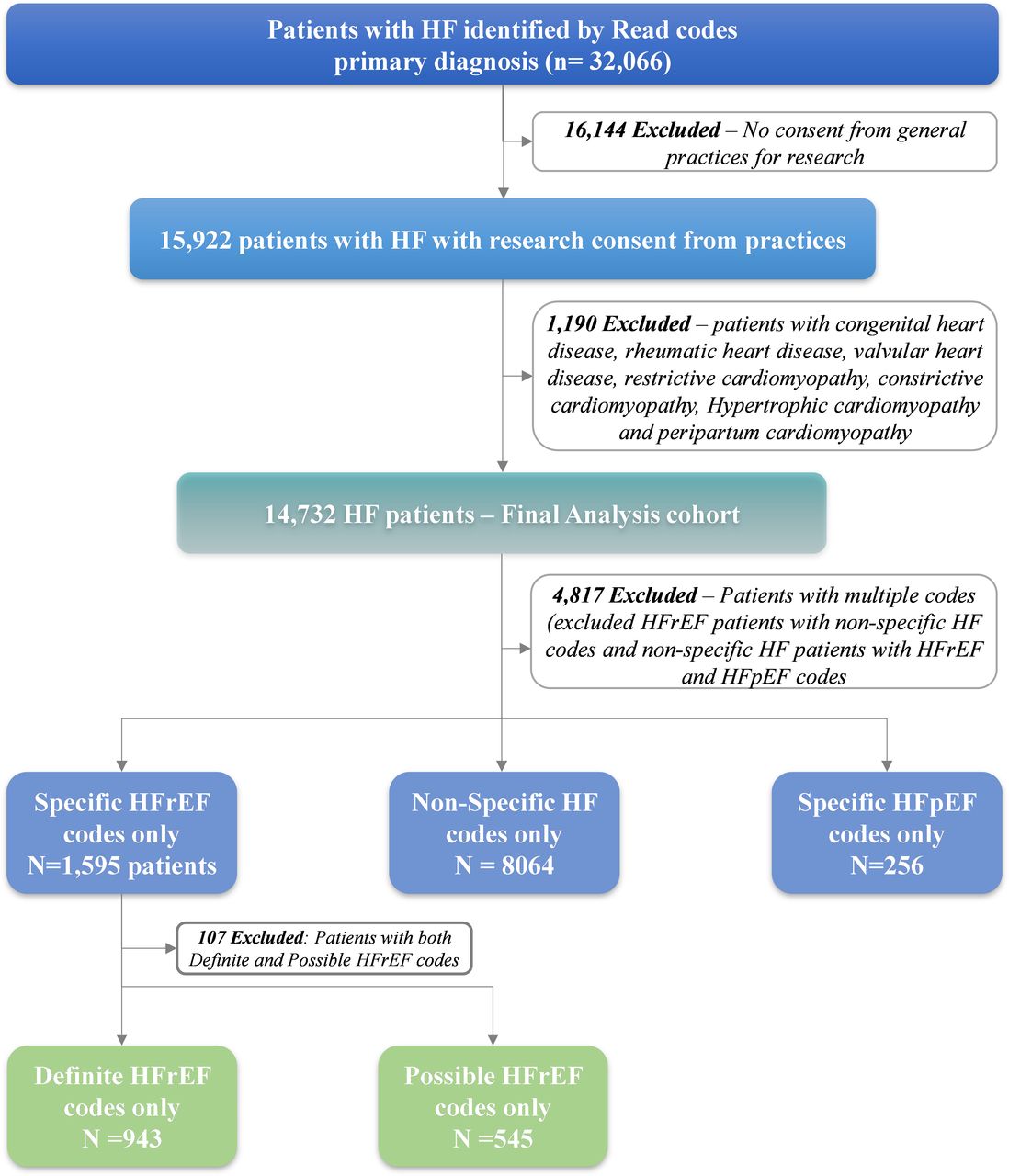
Between 1 January 2015 and 30 September 2017, there were 32 066 patients in the THIN database with any diagnosis of HF ((figure 2). Of these, 16 144 were excluded as their general practices had not consented for research, and, after applying the study inclusion and exclusion criteria the cohort consisted of 10 275 individuals with a primary Read code of HF. Of these, 1595 (15.5%) patients had specific HFrEF codes (including codes suggesting both ‘definite’ and ‘possible’ HFrEF) and 256 (2.5%) patients carried specific HFpEF codes. The majority of patients had non-specific HF codes (n=8424, 82%).

{kind=link}
{kind=link}
Definite HFrEF codes: codes are outlined in online supplemental appendix, for example, HF with reduced ejection fraction, left ventricular systolic dysfunction. Possible HFrEF codes only: codes are outlined in online supplemental appendix, for example, cardiomyopathy, ischaemic cardiomyopathy. HF, heart failure; HFrEF, heart failure with reduced ejection fraction; HFpEF, heart failure with preserved ejection fraction.
From this final cohort of 10 275 patients we randomly selected 500 people to whose GP we then sent the questionnaire. The response rate from GPs was 77.2% (n=386/500). Of these 386 returned questionnaires, 99 were excluded due to missing data on EF, incorrect coding (eg, a clinical assessment suggesting coronary artery disease) or other cause of HF that only became apparent on review of the clinical data (including valvular heart disease, pericardial disease or hypertrophic obstructive cardiomyopathy. Patients with HFrEF at the time of inclusion whose clinical course included recovery of LV function (HFrecEF) were categorised as HFrEF (n=6).
Baseline characteristics
Final analyses included 197 patients with a confirmed diagnosis of HF with impaired EF (<50%) and 90 patients with HFpEF (LVEF ≥50%)table 1). Patients with confirmed HFpEF were older than those with HF with impaired EF (mean age 76.2±8.9 years vs 68.2±8.9 years). HFpEF patients also had a higher prevalence of obesity, chronic kidney disease, atrial fibrillation and hypertension than those with HFrEF. The rate of comorbidities in the HFpEF group is likely to be an overestimate of the true burden of comorbidities since these patients were sampled based on the pre-existing co-morbidities (ie, risk factors) to increase the likelihood of capturing the patient population. On the other hand, patients with HF and impaired EF were not sampled based on risk factors such that the comorbidity burden in this group is more likely to reflect the true burden of comorbidities. HF impaired EF patients were more likely than HFpEF patients to be prescribed ACEI, betablockers and MRA.
Patient characteristics of major HF phenotypes and HF with impaired EF subgroups
Patients with impaired EF (EF <50%) were further categorised into those with HFrEF according to the ESC guidelines (EF <40%) and those with HFmrEF (EF 40%–49%). There were no significant differences in baseline characteristics and comorbidities between those with HFrEF and those with HFmrEF, except for the prevalence of coronary artery disease (CAD), which was higher in those with HFmrEF. Overall HFmrEF and HFrEF patients were also similar in terms of age and co-morbidities and the use of medical therapies, except MRA use which was higher in HFrEF than HFmrEF. In view of the small number of HFmrEF patients and their similarity to the HFrEF patients, we did not undertake further analysis of HFmrEF patients separately from the HFrEF group.
PPV of algorithms for HF with impaired EF
The PPV of the algorithms to detect HF with impaired EF are summarised in table 2. Algorithms that included 3/3 agents to treat HFrEF had acceptable (>80%) PPVs even if the diagnosis Read codes was non-specific. Those with Read codes of definite or possible HFrEF remained over 80% PPV with 2/3 medical treatments for HFrEF. The PPV of non-specific HF codes were high when used in combination with 3/3 GDMT or with 2/3 GDMT in combination with echocardiogram. The other algorithms with non-specific HF codes had much lower PPV (<60%)
Performance of algorithms to detect HF with impaired EF
PPV of algorithms for HFpEF
The PPV of various HFpEF algorithms are summarised in table 3. Only algorithms including specific HFpEF codes had an acceptable PPV. All algorithms using non-specific HF codes and risk factors of HFpEF had a very low PPV.
Performance of algorithms to detect HFpEF
Discussion
Our aim was to determine whether the two distinct phenotypes of HF could be identified using EHR Read codes and to identify which additional information would be required to achieve an adequate PPV, with the long-term aim of providing algorithms useful to groups using EHR data for population-based research and care quality assessment work.
Our findings are first that despite vastly improved access to echocardiography in both primary and secondary care over the last 10 years, only a small proportion (18%) of the overall HF patient population in the UK are coded with specific HF phenotype Read codes in UK primary care practice. Second, we have described that a simple algorithm incorporating combination medical therapy and any HF Read code can reliably identify patients with HF with impaired EF. Third, we have confirmed previous data from observational studies that patients with HFrEF differ little in terms of clinical features or treatment patterns from patients with HFmrEF. Hence, it is unlikely that the algorithms for identifying HF with impaired EF will be able to have the power to discriminate between these subtypes of HF with impaired EF. Fourth, we have described that in the absence of a specific read code, patients with HFpEF cannot be reliably identified from EHR data.
Population-based HF research using EHR has consistently limited due to the unavailability of LVEF measurements which form the backdrop to treatment patterns and outcomes measures in patients with signs and symptoms of HF. However, our data suggest that an algorithm including medical therapy and a non-specific Read code can act as an adequate proxy. This was not the case for HFpEF, where despite the addition of established risk factors for the condition, no improvement in the discriminative performance was observed.
Opportunities and limitations of EHR data
On the one hand, establishing the prevalence and incidence of HFrEF in a primary care database could help coordinate care, plan strategic changes to the location and volume of primary and secondary care services, and monitor the use of ancillary services. However, while the data from EHR can be used to identify HFrEF, the need to include medical treatments in the algorithms to achieve an acceptable PPV is a major limitation. This restricts the ability to assess treatments to those additional to the three core drug groups. While this could be of benefit in providing rapid equity of access and implementation of new treatments, there is a risk that the treatment gap for suboptimally managed patients with HFrEF widens. Hence, the limitations of these algorithms should be appreciated and rapid progress is needed to create alternative ways to leverage routinely collected EHR data for the benefit not just of people with proven HFrEF already on good therapy. While these could take the form of natural language processing (NLP) to identify EF from the unstructured text files in EHR, a faster alternative would be to ensure more accurate and detailed coding within routinely collected primary care data.
Why does widespread non-specific coding matter and how to deal with it?
The management of HF varies greatly by phenotype, yet our data demonstrate that coding of HF in primary care is suboptimal with fewer than one in five patients with HF being assigned a code that could help determine pathways of care. Our analysis was not designed to identify the underlying reasons for this seeming lack of fidelity in coding, although our data collection process revealed that primary care teams frequently have available to them the information required to enter these specific codes. One underlying mechanism therefore could be lack of experience or training in those team members entering these data.
A possible solution could be better communication of coding information between primary and secondary care. The phenotype of patients discharged following a hospital stay or seen in a specialist clinic is communicated in written form, but adding coding to these documents could improve this. It is possible for example that more careful coding with a translation of clinical documentation to definite HFrEF codes could be associated with more effective achievement of guideline directed therapy and where quality of care is reimbursed, coding could be used to encourage appropriate prescribing of treatments in HFrEF and the avoidance of inappropriate unproven prescribing in people with HFpEF. As described.
The difficulty in diagnosing HFpEF using EHR reflects the challenges of diagnosing and managing the condition in the clinical arena. A clinical diagnosis of HFpEF requires clinical signs and symptoms, raised natriuretic peptides and evidence of cardiac dysfunction.14 yet despite these features, the disease remains heterogeneous in phenotype making treatment on the whole based around symptoms and risk factor control. Patel et al developed a highly sensitive algorithm for identification of detection of HFpEF in the Veteran’s affair national database.15 However, the algorithms included an NLP to identify EF from the unstructured text files in EHR.
The findings of this study reinforce the notion that HFmrEF may be a phenotypic subset of HFrEF as opposed to a separate phenotype.16 17 The similarities in pharmacotherapy use between the two groups (HFmrEF and HFrEF) signify that physicians in routine clinical practice might also be approaching these two groups of patients as one. Contrary to previous registry and clinical trial data, the crude prevalence of coronary artery disease was higher in HFmrEF compared with HFrEF,18–20 a finding which warrants confirmation with further studies.
Limitations
This study has important limitations. While there was a reasonable response rate (>75%), additional patients were excluded due to lack of data on EF. Although the PPVs of several algorithms were adequate for the identification of HFrEF, the wide CIs underscore the uncertainty inherent in these algorithms in the presence of a modest sample size. Moreover, as discussed, although our approach can identify people with HF with impaired EF, the power of the algorithms in those with possible or non-specific coding is driven by the medical therapy. Hence, these algorithms are unsuitable to look at the penetration of optimal medical therapy or for identifying people who might benefit from treatment optimisation unless this takes the form of additional therapy beyond the three agents included in the described algorithms. Our dataset was too small to compare coding practices across primary care although this is an important issue when attempting to provide equity of care. Our data were collected from the THIN database from primary care in the UK and may therefore not be generalisable to other healthcare systems. This study was performed in the UK, and hence may limit generalisability of the results to EHR databases from other countries.
Conclusions
This prospective validation study from nationwide EHR showed that prescriptions HF medications can reliably be used to identify HFrEF patients in the UK and therefore could be used to undertake pharmacoepidemiologic assessment of new treatments or management options in HFrEF patients already taking guideline directed medical therapy. Algorithms using non-specific HF codes and structured clinical parameters could not reliably identify HFpEF patients. While building (NLP tools to capture imaging data could be useful for the accurate use of legacy datasets, accurate coding based on imaging-guided phenotyping in secondary care, communicated effectively could render this less critical in the future.
Data availability statement
Data may be obtained from a third party and are not publicly available. No data are available. No data area available for onward sharing from this study.
Ethics statements
Patient consent for publication
References
Supplementary materials
Supplementary Data
This web only file has been produced by the BMJ Publishing Group from an electronic file supplied by the author(s) and has not been edited for content.
Footnotes
VS and RZ are joint first authors.
VS and RZ contributed equally.
Presented at This paper is based on the first author’s published thesis: https://spiral.imperial.ac.uk/handle/10044/1/96995
Contributors JKQ and VS conceived the study and research question and all authors contributed to study design. VS and RZ conducted all data analyses. VS drafted the manuscript. All authors contributed to the editing and revision of the manuscript and approved the final manuscript prior to submission. JKQ accepts full responsibility for the work and/or the conduct of the study, had access to the data, and controlled the decision to publish
Funding This study was funded by Bayer through a grant awarded to Imperial College London.
Competing interests JKQ reports grants from MRC, HDR UK, GSK, BI, asthma+lung, Chiesi and AZ and personal fees for advisory board participation or speaking fees from GlaxoSmithKline, Boehringer Ingelheim, AstraZeneca, Chiesi, Teva, Insmed and Bayer. Imperial College received funding from Bayer for JKQs research group to undertake this work. RZ reports personal fees from AstraZeneca, KKW reports income to University of Leeds from Medtronic, Heart Research UK, NIHR and BHF and personal fees from Bayer, Medtronic, Abbott, Cardiac Dimensions, Novartis and BI.
Provenance and peer review Not commissioned; externally peer reviewed.
Supplemental material This content has been supplied by the author(s). It has not been vetted by BMJ Publishing Group Limited (BMJ) and may not have been peer-reviewed. Any opinions or recommendations discussed are solely those of the author(s) and are not endorsed by BMJ. BMJ disclaims all liability and responsibility arising from any reliance placed on the content. Where the content includes any translated material, BMJ does not warrant the accuracy and reliability of the translations (including but not limited to local regulations, clinical guidelines, terminology, drug names and drug dosages), and is not responsible for any error and/or omissions arising from translation and adaptation or otherwise.